In een paar uur werkend: van losse MP3's naar sprookjesspeler-app
Intro
Mijn zoontje van 4 tikt nu zelfstandig sprookjes aan op de iPad. Hij kiest op basis van een plaatje, de tekst loopt mee terwijl hij luistert, en als hij morgen terugkomt weet de app nog waar hij gebleven was.
Dat begon met een doos oude Lekturama-cassettebandjes die ik op zolder vond.
Ik vond vervolgens een flinke verzameling losse MP3's van die verhalen. Praktisch had een kleuter daar weinig aan. Daarom wilde ik een simpele (podcast-)speler met grote plaatjes: tikken en luisteren. Liefst met meerdere profielen, positie onthouden en als het kon ook meeleestekst.
Wat begon als "ik knutsel even iets in elkaar" was na een paar uur al werkend. Daarna heb ik er nog een dikke werkdag in gestopt om alles te finetunen tot het eindresultaat in de screenshots. In dit artikel loop ik door het hele proces heen: de technische keuzes, de missers onderweg en wat AI daarin wel en niet voor me deed.
Niet zo technisch? Klik hier voor de simpele uitleg
Dit is de korte versie in gewone taal.
1. Het idee
Ik vond mijn oude sprookjes terug en wilde die doorgeven aan mijn zoontje van 4. Maar losse MP3-bestanden in een map zijn voor een kind niet bruikbaar.
2. Wat ik heb gemaakt
Ik heb een simpele iPad-app gebouwd met grote knoppen en plaatjes. Hij kan zelf kiezen, luisteren en later weer verdergaan waar hij was gebleven.
3. Waarom die plaatjes belangrijk zijn
Mijn zoontje begint met lezen. Met herkenbare illustraties kan hij verhalen kiezen op beeld in plaats van op tekst.
4. Wat AI hier deed
AI hielp op drie plekken: meedenken over de opzet, illustraties maken en gesproken audio omzetten naar meeleestekst. Zie het als een snelle assistent, niet als automatische piloot.
5. Belangrijk: alles draait lokaal
Alle verwerking gebeurde op mijn eigen server en laptop thuis. De verhalen hoefden dus niet naar een externe cloudservice.
6. Het resultaat
Van een rommelige map met losse MP3's naar een app die mijn zoontje echt zelfstandig gebruikt. Dat was precies het doel.
TL;DR: Ik bouwde op mijn homelab een React + FastAPI + SQLite app voor de iPad, met karaoke-achtige meeleestekst via Whisper, ongeveer 400 AI-illustraties via ComfyUI waarvan de prompts gegenereerd worden door LM Studio (Qwen). Het heeft ondersteuning voor meerdere profielen en een complete backend voor import en configuratie. De app draait als Docker-container en is als PWA te openen. Belangrijk: de verwerking draait lokaal op mijn eigen hardware (homelab + laptop), niet in een externe cloud.
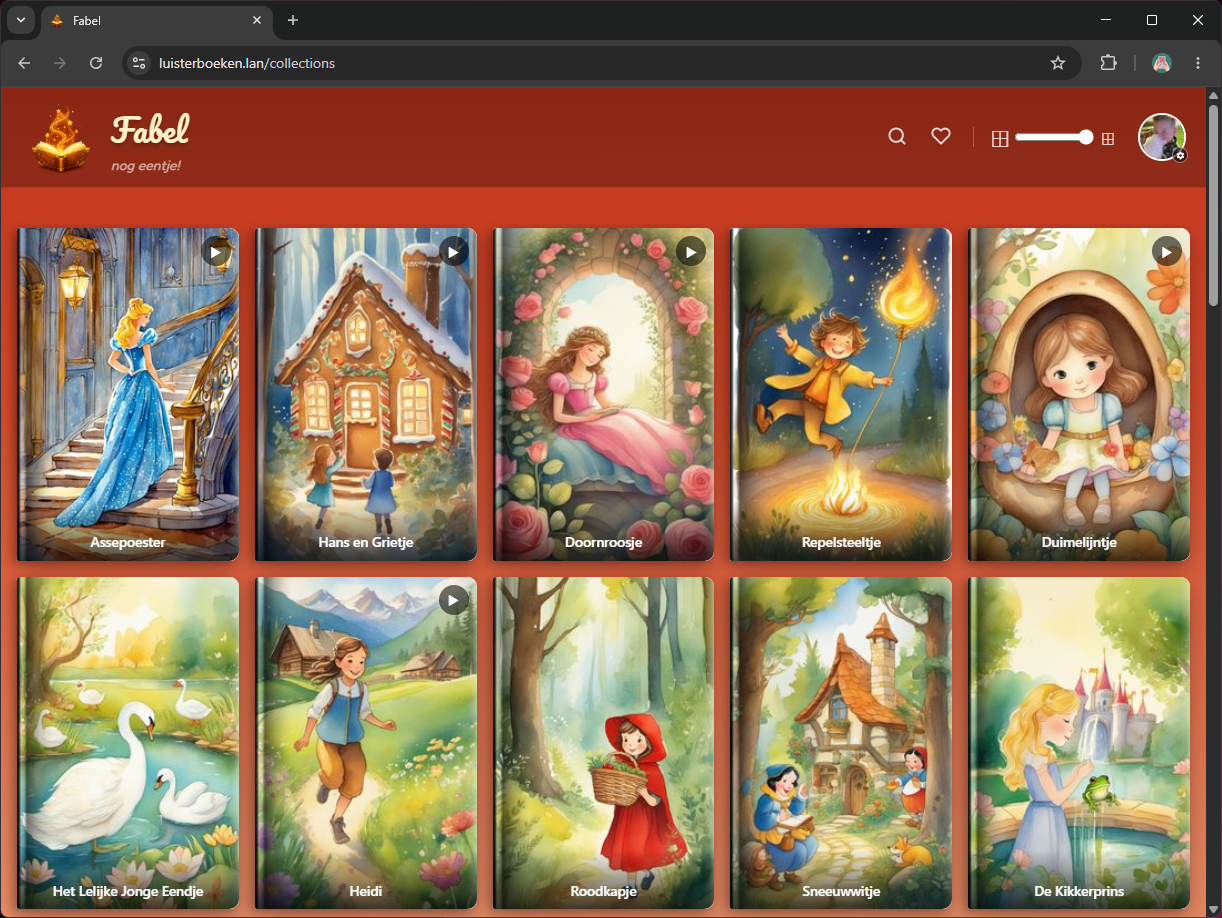
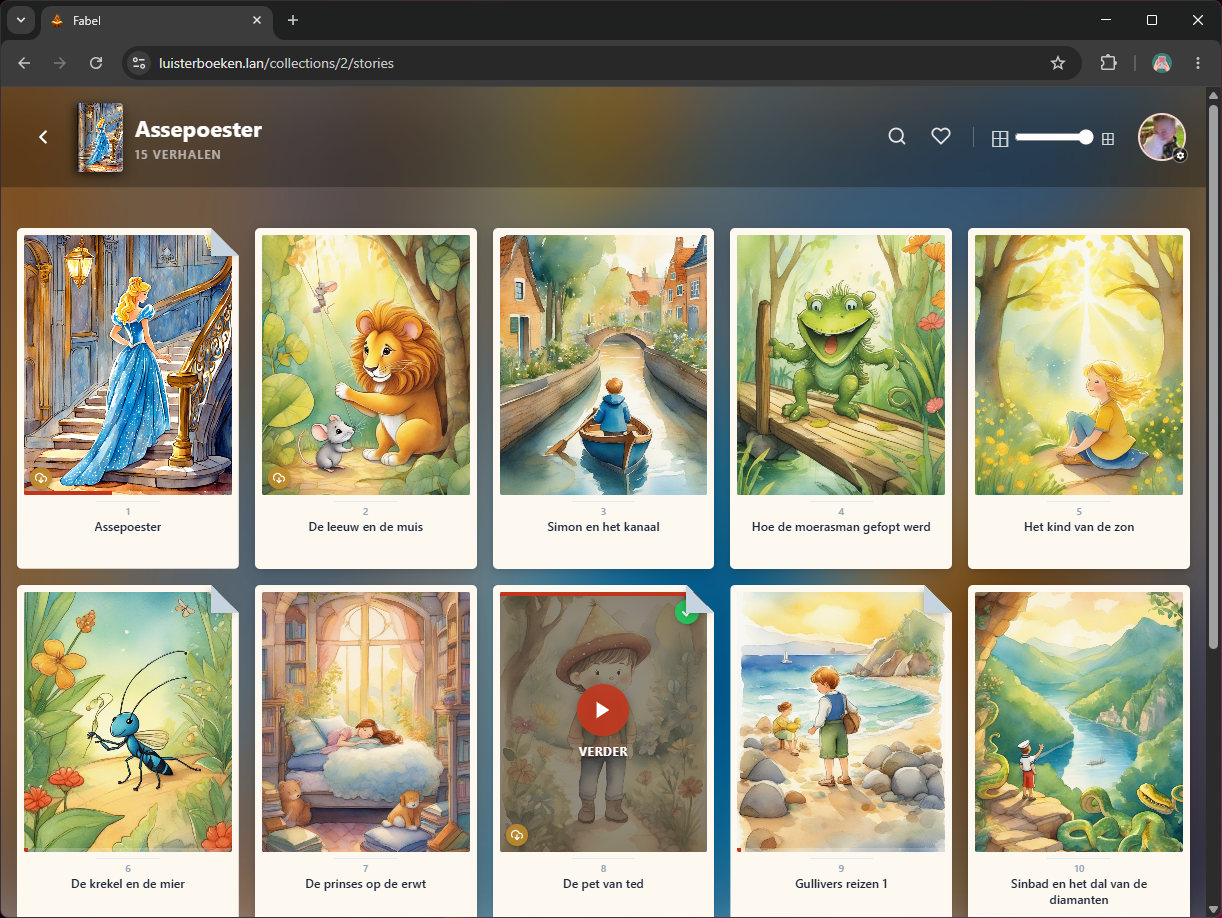
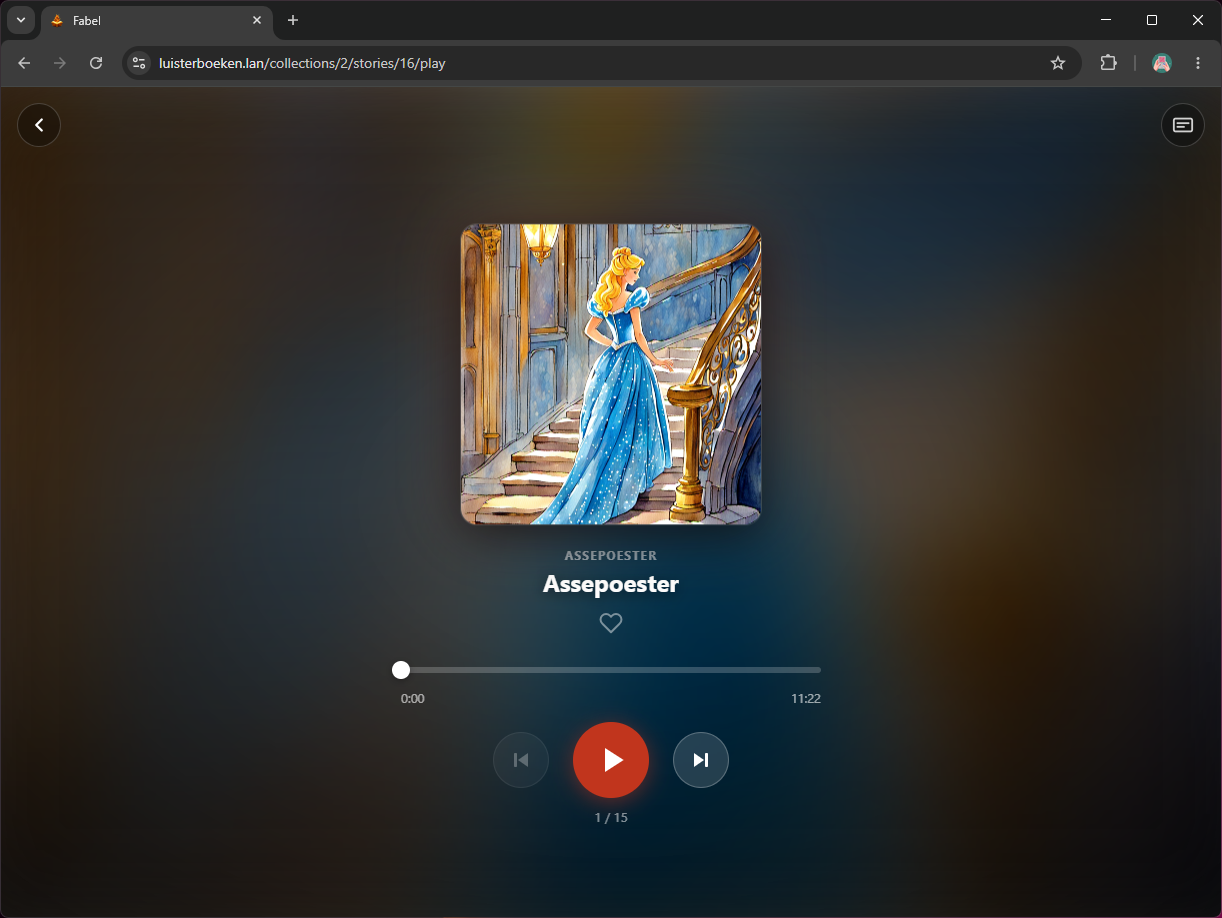
De uitgangssituatie
Hardware
- Een compacte homelab-server waarop Docker draait
- Een NAS voor opslag van media en projectbestanden
- Een Windows-laptop met GPU (4070) voor de zware AI-taken
- Nginx Proxy Manager, AdGuard Home en Tailscale als basisinfra
De content
Ongeveer 60 MP3-bestanden, elk een verhaal, bestandsnaam als lekturama01 het lelijke jonge eendje.mp3. Het prefix geeft de bundel aan, de rest de titel.
Stap 1: De prompt
Ik ben begonnen met Claude, gewoon in de chat-app en niet in Copilot, om de requirements scherp te krijgen. Nog geen code dus, maar eerst het idee zelf: wat moet de kinder-UI kunnen, hoe werkt de admin, welk datamodel is logisch en hoe zet je dit netjes in Docker Compose. Daar rolde een forse prompt uit die ik daarna in VS Code aan Copilot gaf.
Belangrijke keuzes die uit dat gesprek kwamen
- React (TypeScript) + FastAPI + SQLite, licht genoeg voor een homelab maar prima voor deze features
- Twee volledig gescheiden UI's: kinder-UI op
/(grote touch-targets, geen tekst nodig), admin op/admin - Auto-import endpoint dat de mediamap scant en bundels/verhalen aanmaakt op basis van bestandsnamen
- Profielen zonder wachtwoorden (het zijn kinderen van 4)
- PWA zodat het fullscreen draait op de iPad
Wat ik hiervan leerde: tijd steken in goede requirements loont echt. Copilot spuugde daarna in een keer een backend- en frontend-structuur uit waar ik verrassend weinig aan hoefde te sleutelen.
Stap 2: Van prompt naar werkende app
In deze stap moest het vooral bruikbaar worden: profiel kiezen, verhaal starten en voortgang onthouden. Copilot zette daarvoor in één keer een werkende basis neer voor zowel de app als de achterkant.
Eerste hobbels
- CSS Module-bestanden ontbraken, dus wel
.module.css-imports maar geen bijbehorende bestanden. Daar was nog een TypeScript-declaratie voor nodig. - Docker volume mounts met spaties in het pad gingen mis omdat ik de aanhalingstekens was vergeten
- Dev-workflow: elke wijziging vereiste een
docker compose up --build. Oplossing: backend en frontend lokaal draaien metuvicorn --reloadenvite dev - Vite had cacheproblemen bij hot reload, opgelost met
/tmp/vite-cachealscacheDir
Na die eerste fixes werkte het al verrassend goed. Ik kon profielen aanmaken, de import draaien en verhalen afspelen met positie onthouden. Wel nog zonder illustraties: alleen tekst en gekleurde placeholder-tegels.
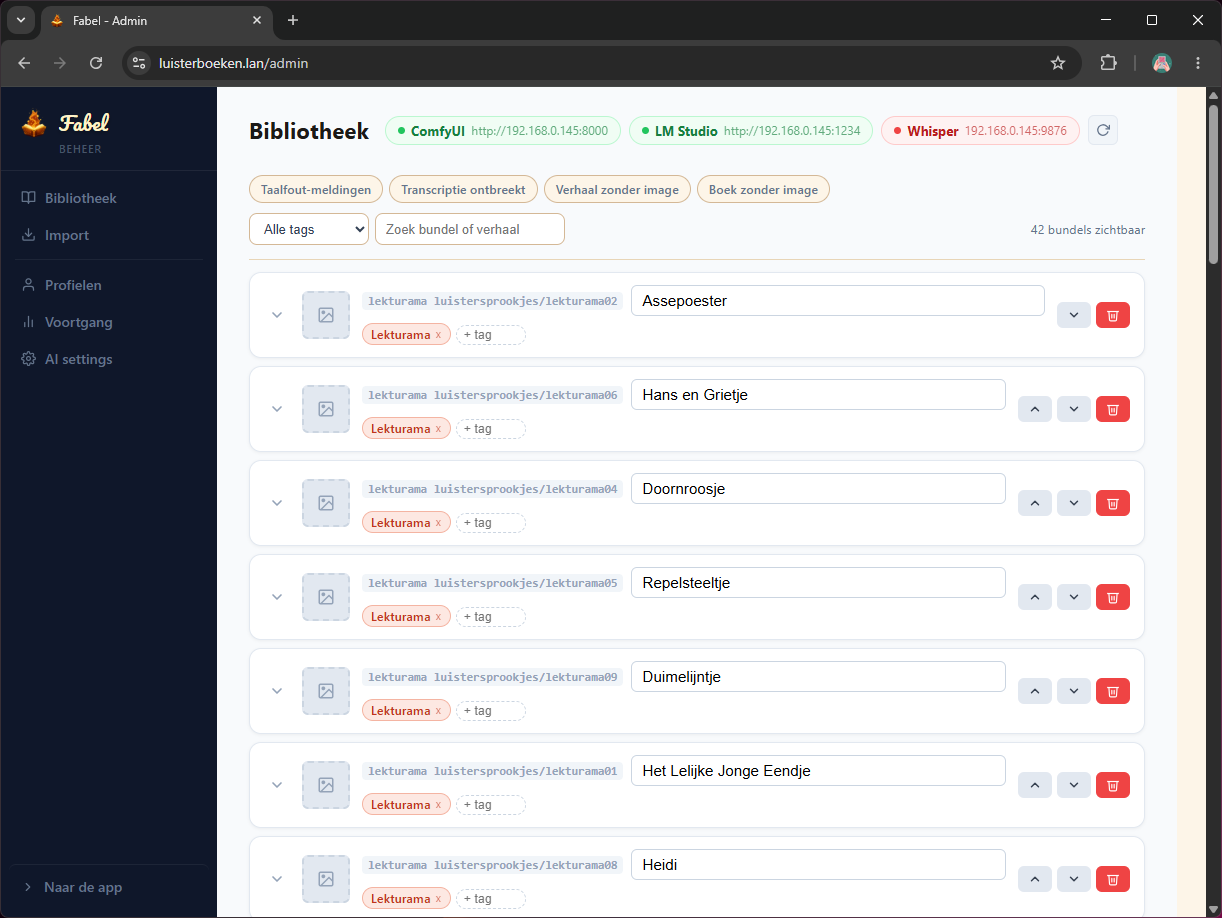
Tot daar werkte alles functioneel, maar nog niet echt zelfstandig voor een kind van 4. Met alleen kleurvlakken of tekst kon hij niet zelf kiezen wat hij wilde horen. Herkenbare illustraties waren dus geen extraatje, maar het navigatiemiddel.
Stap 3: 400 illustraties genereren met AI
Hier kwam het verschil tussen “werkt” en “zelfstandig bruikbaar”. Zonder plaatjes kon mijn zoontje niet zelf kiezen, dus voor elk verhaal was een herkenbare illustratie nodig.
De pipeline
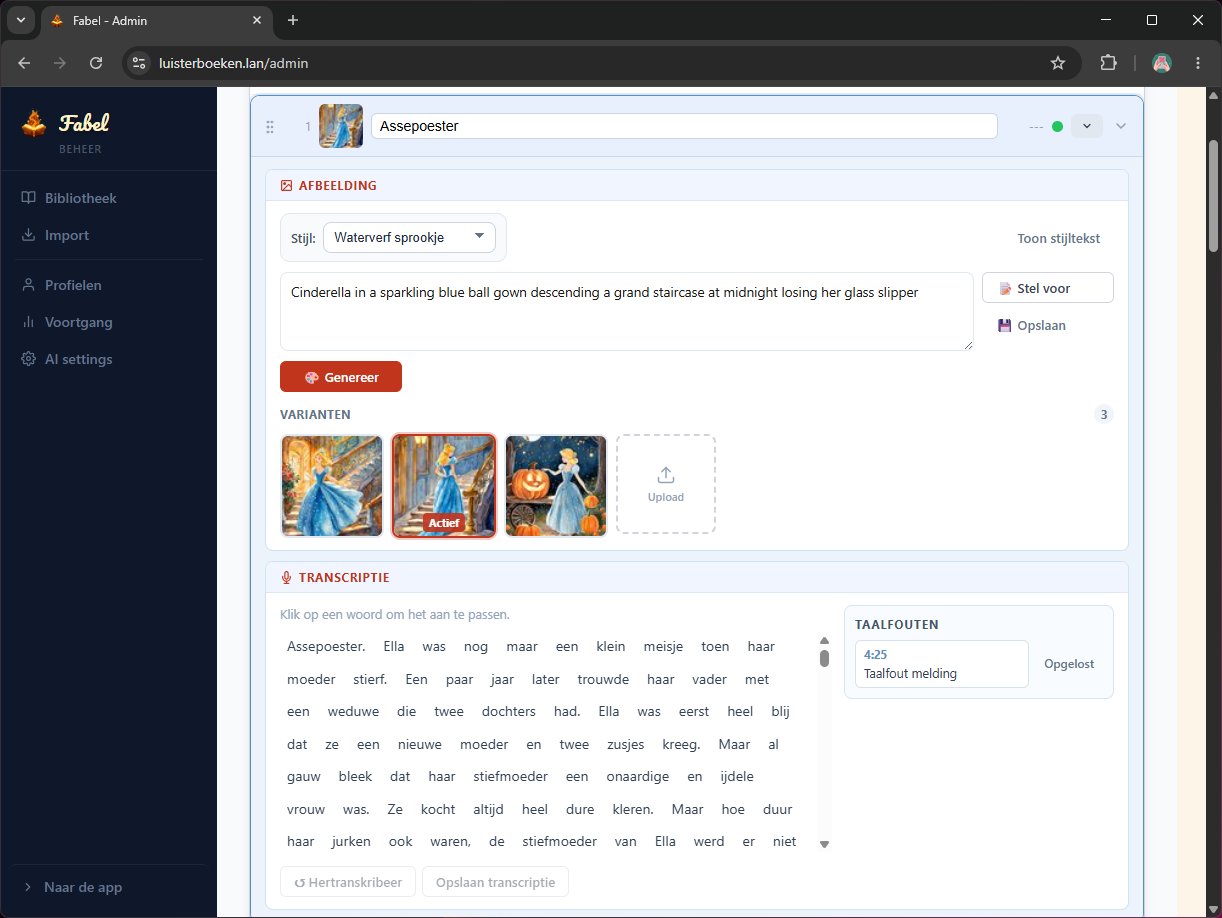
- Scene-beschrijvingen maken: een Python-script haalde de verhaaltitels op en liet daar per bundel passende scene-beschrijvingen bij schrijven via Qwen in LM Studio. Later heb ik die prompt verbeterd met highlights uit de transcriptie.
- Afbeeldingen genereren: hetzelfde script stuurde die beschrijvingen naar ComfyUI (SDXL, 832x1216) en haalde de beelden weer op. Op de RTX 4070 duurde dat ongeveer 20 seconden per afbeelding.
- Automatisch koppelen: daarna uploadde het script elke afbeelding en koppelde die meteen aan het juiste verhaal.
Batch draaien (overnight):
nohup python3 generate_illustrations.py --no-refiner > generate.log 2>&1 &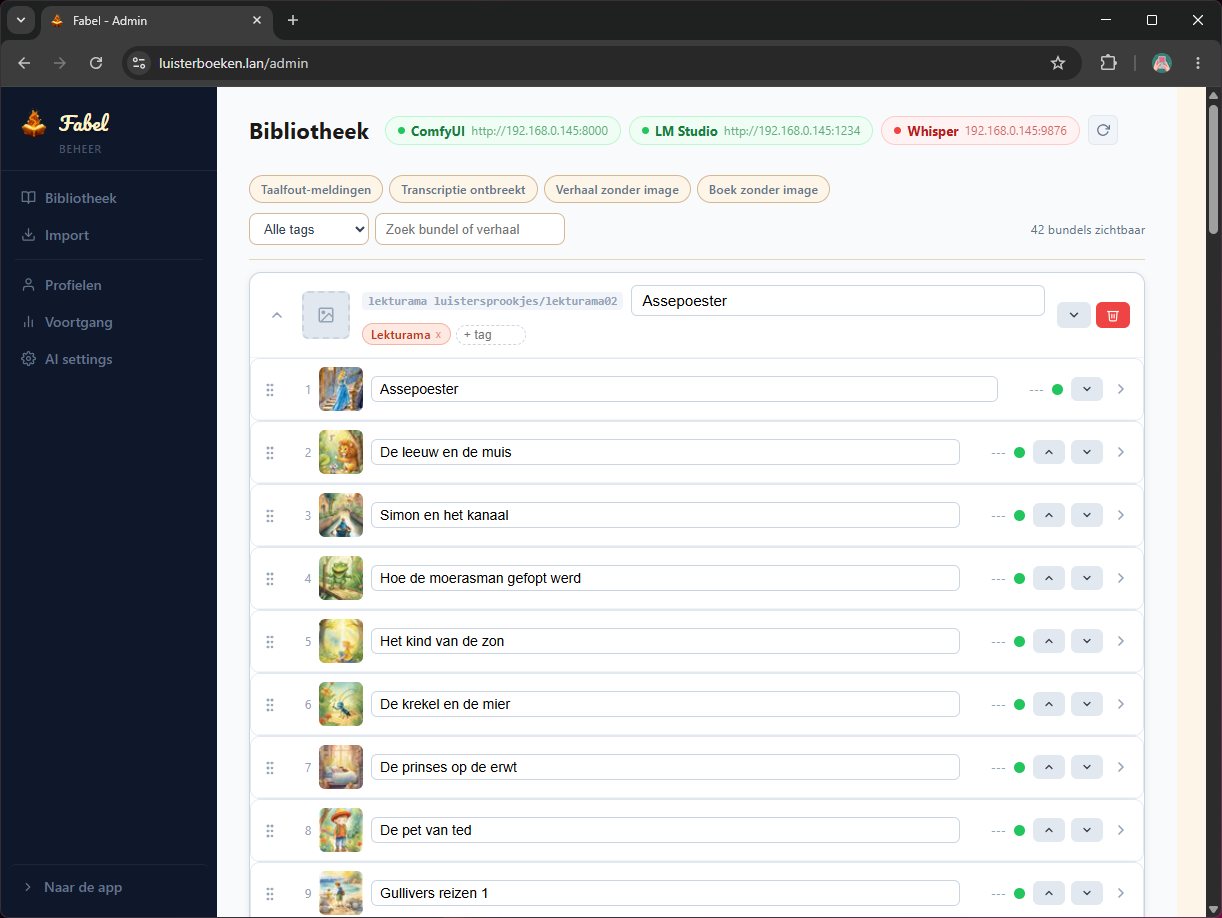
Wat niet meteen werkte
- LM Studio stond met thinking mode aan, waardoor het model al zijn tokens aan redeneren opmaakte en vervolgens met lege responses kwam. Oplossing:
/no_thinkvoor de prompt zetten. - CUDA DLL's werden op Windows niet gevonden. Dat heb ik opgelost met
os.add_dll_directory()voor de NVIDIA-pip-packages. - De eerste promptversie op basis van de titel van het verhaal was te generiek, waardoor alle illustraties op elkaar begonnen te lijken. Juist die LLM-stap voor specifiekere beschrijvingen maakte het verschil.
Stap 4: Karaoke-meeleestekst via Whisper
Daarna wilde ik dat tekst en audio samenliepen, zodat een kind mee kan kijken tijdens het luisteren. Met spraak-naar-tekst kreeg ik per woord de timing, waardoor de speler live het juiste woord kan markeren.
0.00 - 0.32: Er
0.32 - 0.58: was
0.58 - 0.94: eens
0.94 - 1.20: een
1.20 - 1.68: lelijk
1.68 - 2.10: jong
2.10 - 2.58: eendjeDe aanpak
faster-whispermetword_timestamps=Trueop de RTX 4070- Ongeveer 10 seconden per verhaal van 2 minuten (11x realtime)
- Output: JSON array met woord + start/eindtijd
- Opgeslagen als
transcriptionkolom op het Story model - Frontend highlight het actieve woord op basis van
audio.currentTime
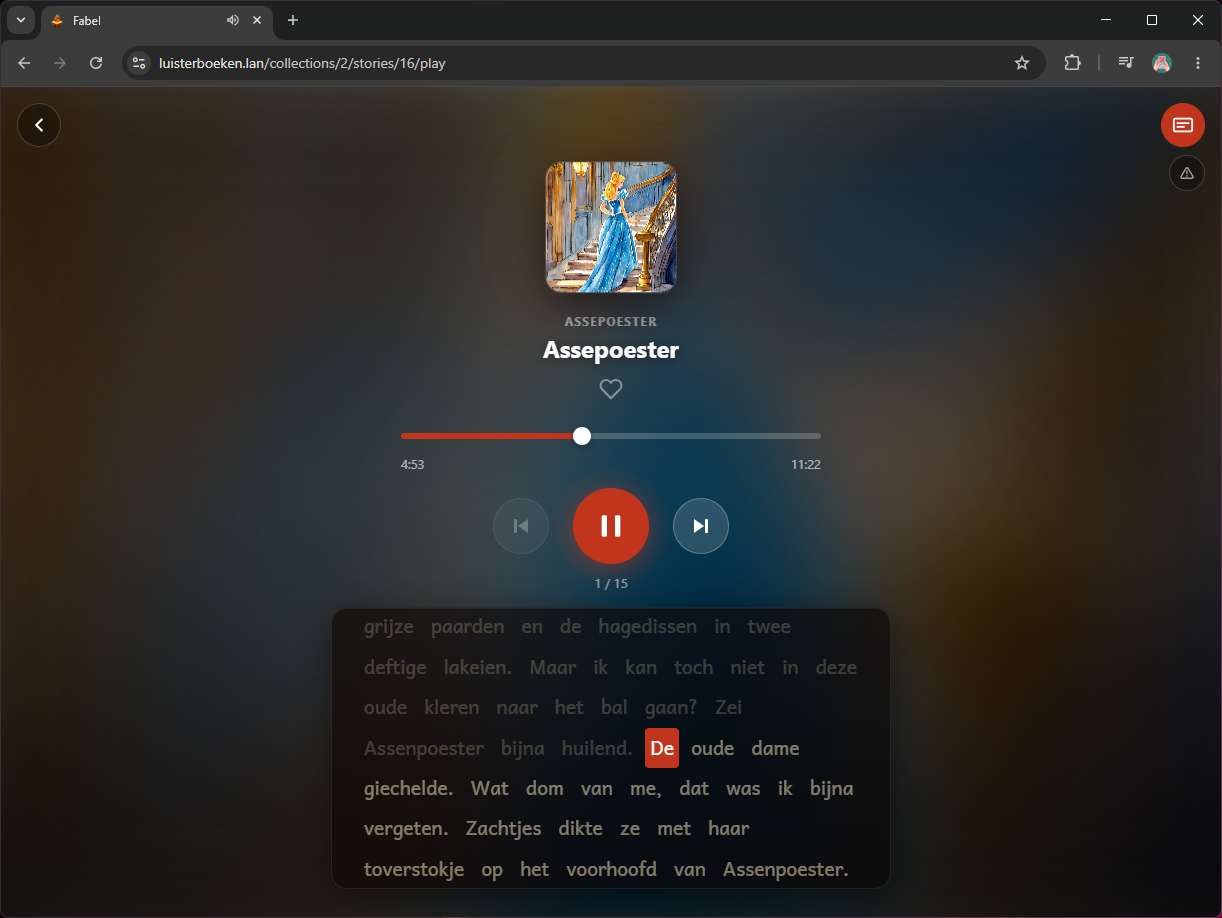
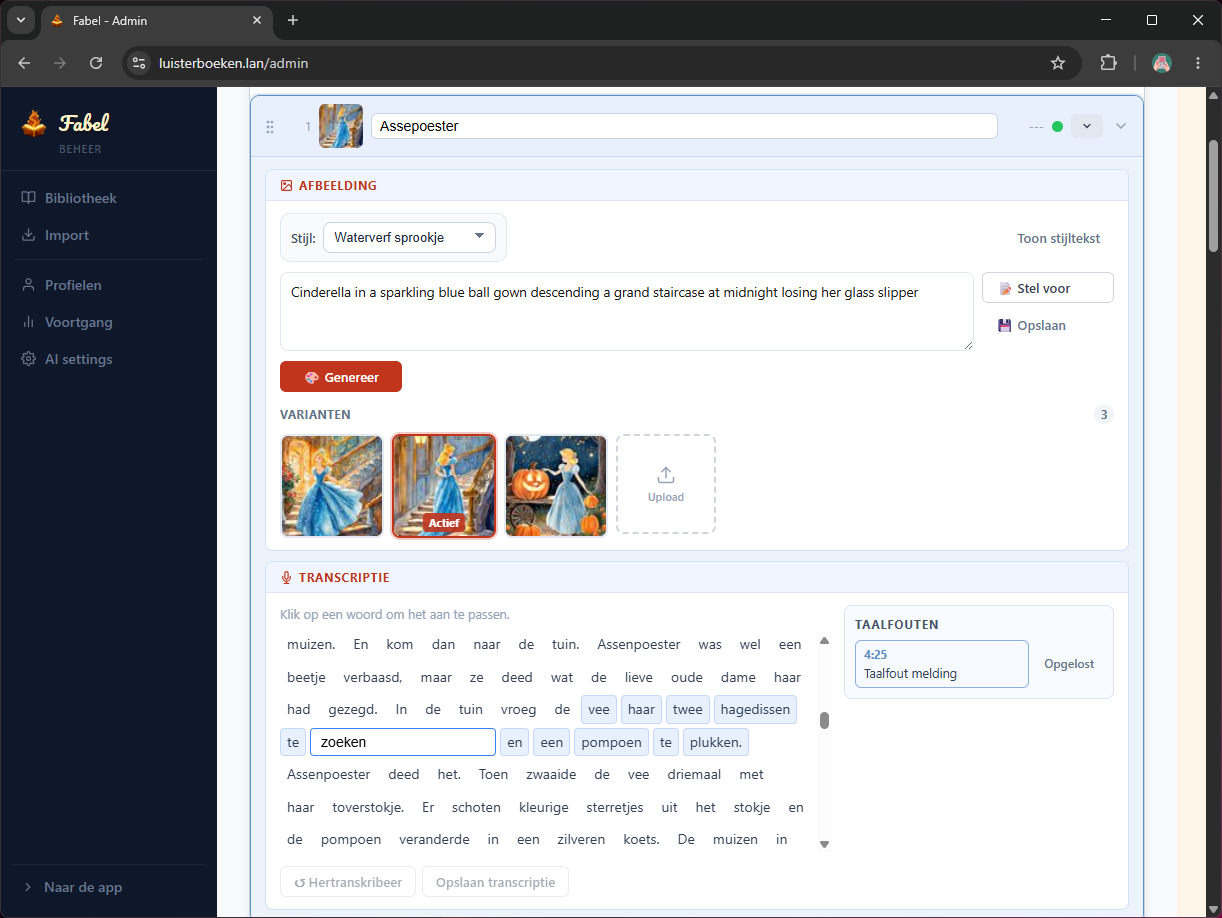
De kwaliteit is verrassend goed voor Nederlands: de timing loopt meestal vloeiend mee. Er zitten soms fouten in (zoals “vee” in plaats van “fee”), daarom heb ik een meldknop toegevoegd zodat ik zulke missers later snel kan corrigeren.
De stack
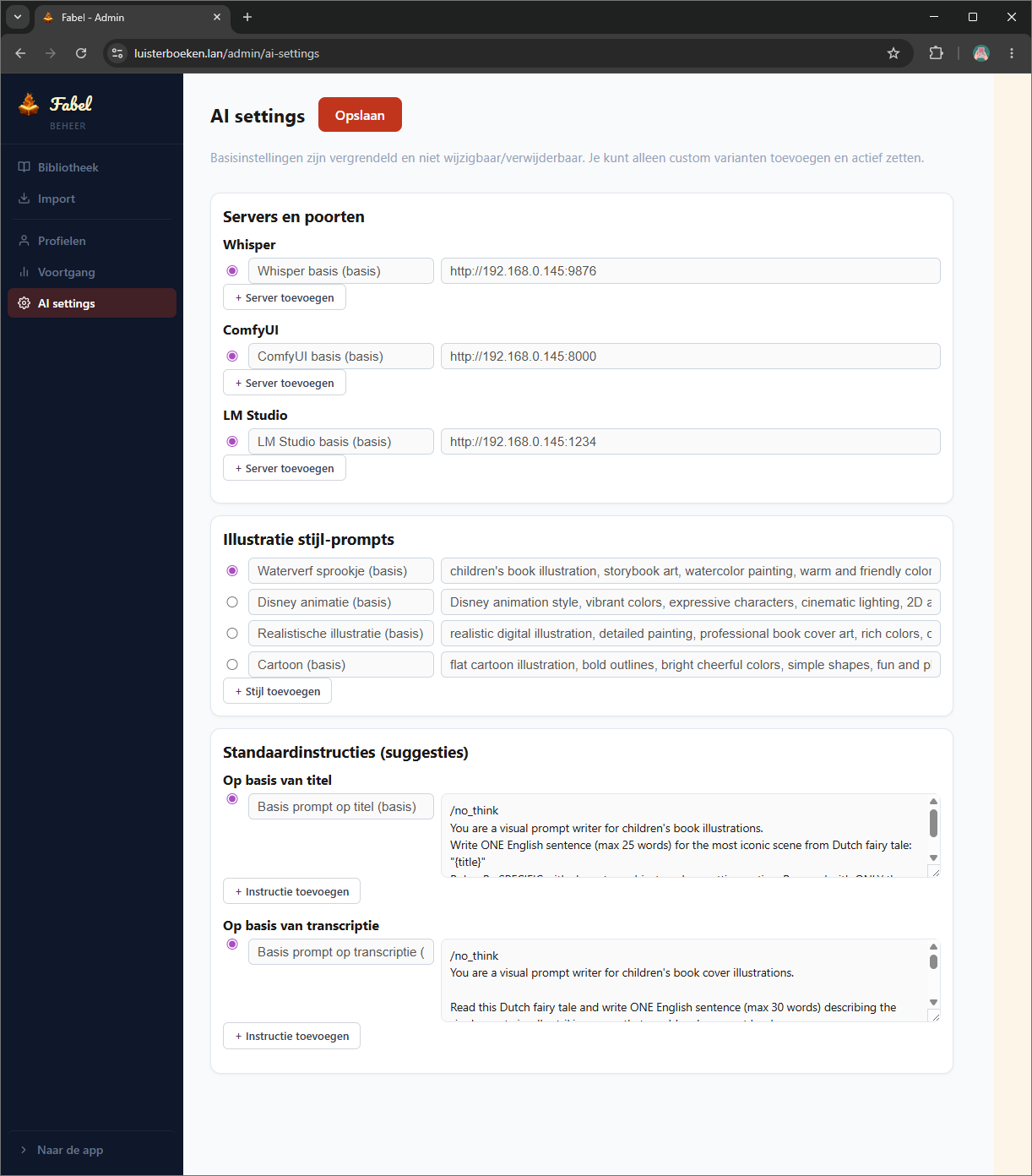
De keuzes zijn bewust licht gehouden. SQLite omdat het één gezin is, geen concurrency en geen reden voor de overhead van Postgres. FastAPI vanwege async en automatische docs die handig zijn tijdens development. React omdat Copilot daar consistent betere code voor genereert dan voor minder gangbare frameworks.
| Component | Technologie |
|---|---|
| Frontend | React (TypeScript), Vite, PWA |
| Backend | Python, FastAPI, SQLAlchemy |
| Database | SQLite |
| Git | Forgejo op HP EliteDesk |
| Hosting | Docker Compose op HP EliteDesk |
| Reverse proxy | Nginx Proxy Manager (luisterboeken.lan) |
| Illustraties | SDXL via ComfyUI API |
| Transcriptie | Whisper large-v3 via faster-whisper |
| Scene-beschrijvingen | Qwen 3.6 35B via LM Studio |
| Prompt-ontwerp | Claude Opus 4.6 (Anthropic) |
| Code-generatie | GitHub Copilot in VS Code |
De rol van AI - eerlijk verhaal
Al die tooling is mooi, maar de vraag is wat je er zelf nog aan doet. Ik wil hier geen opgeklopt AI-verhaal van maken.
Context die voor mij belangrijk is: alle AI-verwerking (illustraties, transcriptie en promptgeneratie) draaide lokaal op mijn eigen machines. De bronbestanden en tussenresultaten bleven dus in mijn eigen omgeving.
Wat AI goed deed
- De eerste architectuur en prompt. Claude hielp me in een kwartier van "ik wil een sprookjesspeler" naar een uitgebreide spec prompt waar Copilot direct iets bruikbaars mee kon.
- Code scaffolding: de complete backend + frontend structuur in een Copilot-sessie.
- Illustraties: honderden unieke, stijlconsistente kinderboek-illustraties zonder ook maar een pixel zelf te tekenen.
- Transcriptie: Whisper deed in een paar uur wat handmatig weken zou kosten.
- Probleemoplossing. Ik kon foutmeldingen in de chat gooien en had vaak snel een bruikbare fix of op zijn minst de juiste denkrichting.
Wat AI niet deed
- De beslissingen nemen. Welke stack logisch is, welke UX werkt voor een kind van 4 en wanneer iets goed genoeg is, dat blijft gewoon mensenwerk. Al geeft het wel goede suggesties.
- Foutloos werken. Copilot maakte regelmatig dingen kapot. Ik moest constant controleren en bijsturen.
- Het concept bedenken. "Mijn kind heeft een sprookjesspeler nodig" is geen AI-idee.
De echte tijdswinst: niet omdat elke losse stap ineens razendsnel ging, maar omdat allerlei drempels wegvielen. Zonder AI had ik die illustraties waarschijnlijk niet gemaakt, de transcriptie ook niet, en was het blijven steken bij een simpele HTML5-audiospeler die nooit echt af had gevoeld. Nu werd het iets dat ook echt af is.
Resultaat
Mijn zoontje gebruikt de app nu regelmatig. Hij kan zelfstandig zijn profiel kiezen, een bundel openen, een sprookje aantikken, en luisteren. De illustraties helpen hem herkennen welk verhaal welk is, en de meeleestekst scrollt mee. Als hij morgen terugkomt, onthoudt de app waar hij gebleven was.
In een paar uur stond de basis, en met nog een dag afwerken werd het een app die hij echt zelfstandig gebruikt. Dat maakt dit project voor mij geslaagd. Dat enthousiasme was ook de aanleiding voor een volgend project: een leesapp die hij zelf speelt op zijn iPad.
Vragen / feedback
Als je vragen hebt over de aanpak, de pipeline of een specifiek technisch onderdeel, stel ze dan via mijn contactformulier en ik neem contact met je op.